
Comment apprendre Ceph | La réalité que PERSONNE ne raconte
” Je lance des commandes mais je ne comprends rien. ” Je lis la documentation mais quand quelque chose ne va pas, je ne sais même pas par où commencer. “Je travaille avec Ceph depuis un an et j’ai l’impression d’avoir à peine effleuré la surface. Si l’une de ces phrases résonne en toi, tu n’es pas seul. Et surtout, ce n’est pas de ta faute.
Après plus de 10 ans à travailler avec Ceph en production, à enseigner à des centaines d’administrateurs et à sauver des clusters “impossibles” à 3 heures du matin, nous sommes arrivés à une conclusion que personne ne te dira dans les certifications officielles : Ceph est brutalement difficile à maîtriser. Et ce n’est pas parce que tu es un mauvais administrateur, mais parce que la technologie est intrinsèquement complexe, en constante évolution, et que la documentation suppose des connaissances que personne ne t’a explicitement enseignées.
Nous n’allons pas te vendre un “apprendre Ceph en 30 jours”. Nous voulons te dire la vérité sur la façon dont on apprend vraiment, sur le temps que cela prend, sur les malentendus qui te retiendront, et sur le chemin le plus efficace pour passer du jet aveugle de commandes à une véritable expertise ;).
Pourquoi Ceph est si difficile à apprendre (et ce n’est pas ta faute)
La complexité n’est pas accidentelle : elle est inhérente
Ceph n’est pas “un système de stockage comme les autres”. Il s’agit d’une architecture massivement distribuée qui doit résoudre simultanément :
- Cohérence de l’écriture avec réplication multi-nœuds et consensus distribué
- Disponibilité continue en cas de défaillance du matériel (disques, nœuds, racks complets).
- Rééquilibrage automatique de pétaoctets de données sans temps d’arrêt.
- Performances prévisibles en cas de charges variables et multi-locataires.
- Trois interfaces complètement différentes (bloc, objet, système de fichiers) sur la même base.
- Intégration avec de multiples écosystèmes (OpenStack, Kubernetes, virtualisation traditionnelle).
Chacune de ces capacités distinctes constitue un système complexe. Ceph les intègre toutes. Et voici le problème : tu ne peux pas en comprendre un sans comprendre les autres. 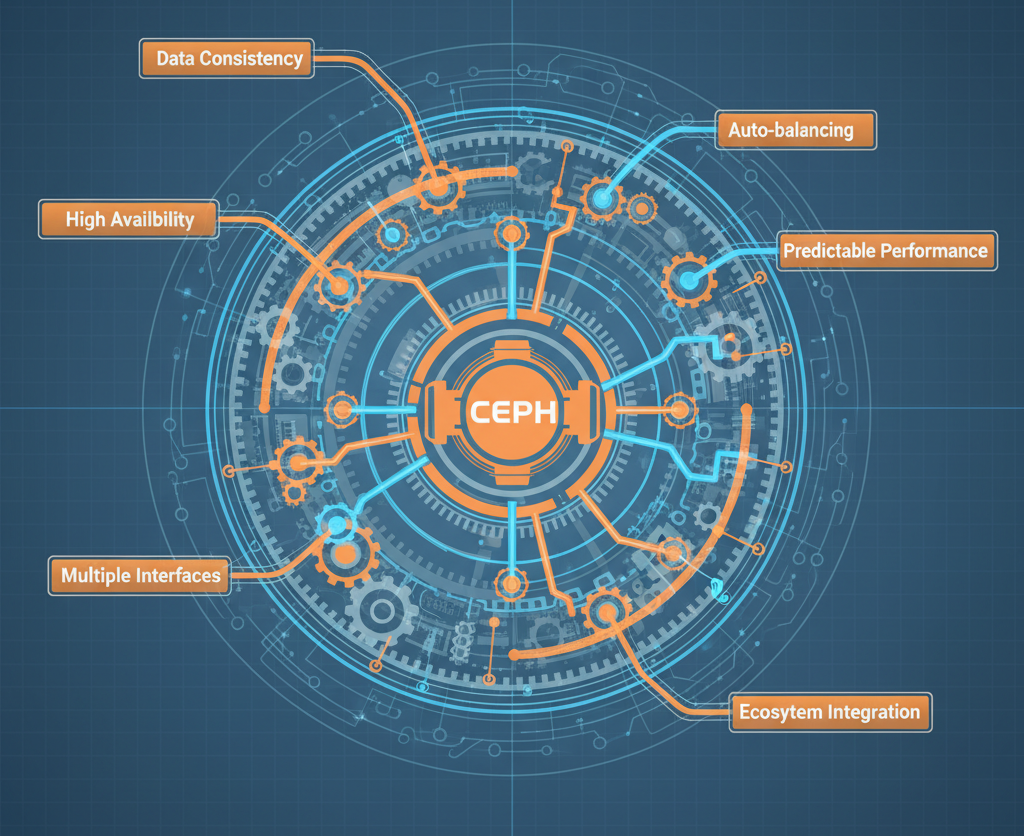
Erreur de débutant #1 : Essayer d’apprendre Ceph comme s’il s’agissait d’un autre service sans état. ” Je configure, je lance des commandes et ça devrait fonctionner. Non. Ceph est un système distribué avec un état partagé, un consensus entre les nœuds et des comportements émergents qui n’apparaissent qu’en cas de charge ou d’échec. Si tu ne comprends pas l’architecture sous-jacente, chaque problème sera un mystère indéchiffrable.
La documentation suppose des connaissances que personne ne t’a apprises
Lis n’importe quelle page de la documentation officielle de Ceph et tu trouveras des termes tels que :
- Groupes de placement (PG)
- Algorithme CRUSH
- BlueStore / FileStore
- Récurage et nettoyage en profondeur
- Peering et récupération
- OSDs up/down vs in/out
La documentation explique ce qu’ils sont, mais pas pourquoi ils existent, quel problème ils résolvent ou comment ils interagissent les uns avec les autres. C’est comme si tu essayais d’apprendre la programmation en commençant par la référence du langage au lieu des concepts fondamentaux.
Exemple concret : un élève nous a écrit : ” Cela fait trois mois que j’essaie de comprendre les PG. J’ai lu qu'” ils sont une abstraction logique “, mais… pourquoi existent-ils ? Pourquoi existent-ils, pourquoi ne pas mapper les objets directement sur les OSD ?”
Cette question témoigne d’une profonde compréhension. La réponse (évolutivité de la carte CRUSH, rééquilibrage de la granularité, surcharge des métadonnées) exige une compréhension préalable des systèmes distribués, de la théorie du hachage cohérent et des compromis en matière d’architecture. Personne ne t’apprend cela avant de publier ceph osd pool create.
L’évolution constante invalide les connaissances
Ceph change RAPIDEMENT. Et je ne parle pas de fonctionnalités optionnelles, mais de changements architecturaux fondamentaux :
- FileStore → BlueStore (2017) : change complètement la façon dont tu écris sur le disque.
- ceph-deploy → ceph-ansible → cephadm (2020) : trois outils de déploiement différents en 5 ans.
- Lumineux → Nautilus → Octopus → Pacific → Quincy → Reef → Squid : 7 versions majeures en 7 ans, chacune avec des changements de rupture.
- Crimson/Seastore (2026+) : Réécriture complète de l’OSD qui invalidera une grande partie des connaissances en matière de réglage.
Ce que tu as appris il y a 2 ans sur le réglage des FileStore n’est absolument pas pertinent aujourd’hui. Les PG par pool que tu calculais manuellement sont maintenant gérés par autoscaler. Les meilleures pratiques en matière de réseau ont changé avec msgr2.
Erreur du débutant (et de l’expert) n°2 : Apprendre des configurations par cœur sans comprendre pourquoi elles existent. J’ai vu un administrateur configurer manuellement le comptage des PG avec des formules lumineuses […] sur un cluster Squid avec autoscaler activé. L’autoscaler l’ignorait, il ne comprenait pas pourquoi. Le contexte historique compte pour savoir quelles connaissances sont obsolètes.
Combien de temps faut-il vraiment pour maîtriser Ceph ?
Parlons avec des chiffres réels basés sur notre expérience de la formation des administrateurs :
Progression réaliste de l’apprentissage
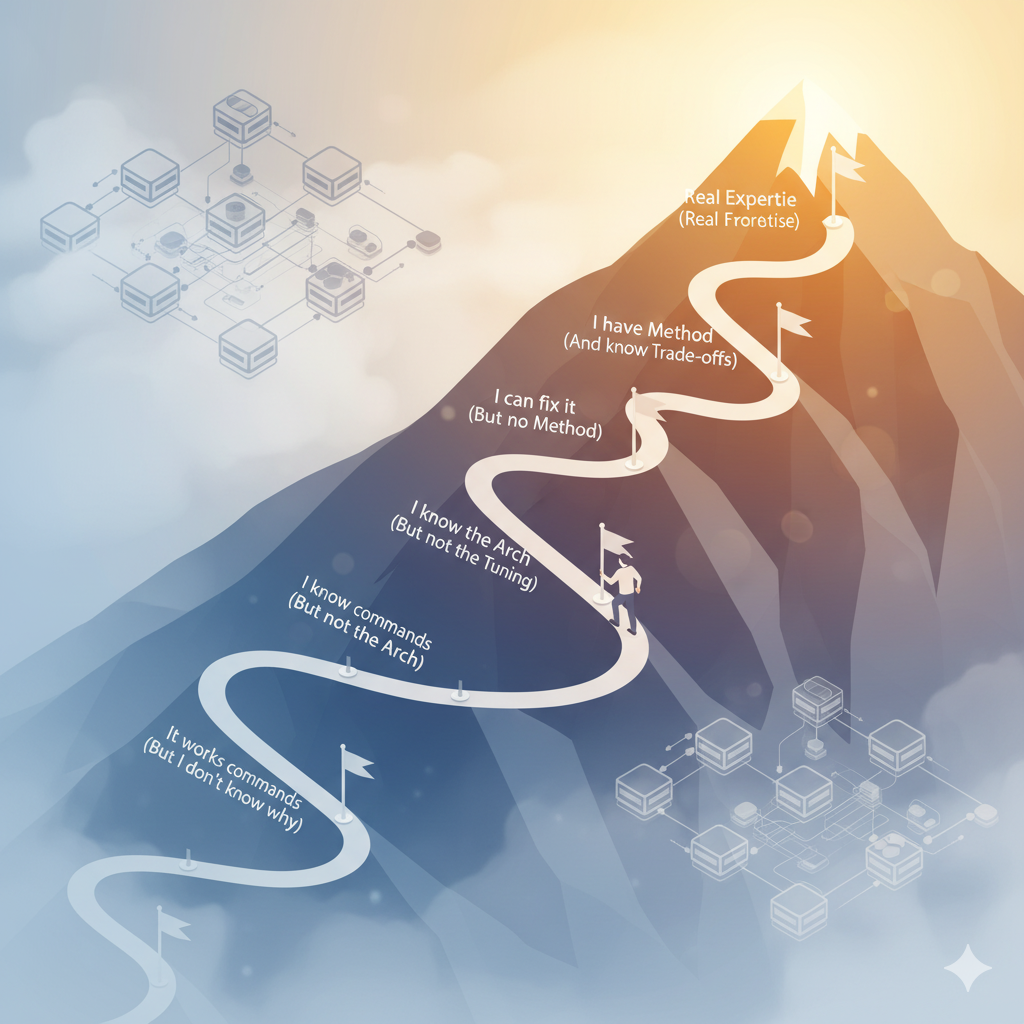
Mois 1-2 : “Je ne comprends rien mais ça marche”.
Tu suis des tutoriels. Tu lances les commandes ceph osd pool create, ceph osd tree. Le cluster fonctionne… jusqu’à ce qu’il ne fonctionne plus. Un OSD est marqué en bas et tu paniques parce que tu ne sais pas comment faire le diagnostic.
Symptôme typique : tu copies des commandes de Stack Overflow sans comprendre ce qu’elles font. “Je l’ai réparé” mais tu ne sais pas comment ni pourquoi.
Mois 3-6 : “Je comprends les commandes mais pas l’architecture”.
Tu as mémorisé les principales commandes. Tu sais comment créer des pools, configurer RBD, mettre en place CephFS. Mais lorsque PG 3.1f is stuck in peering se présente, tu n’as aucune idée de ce que signifie “peering” ou de la façon de résoudre le problème.
Symptôme typique : tu résous les problèmes par essais et erreurs en redémarrant les services jusqu’à ce que ça marche. Il n’y a pas de méthode, il y a de la chance.
Mois 6-12 : “Je comprends l’architecture mais pas le réglage”.
Tu comprends enfin MON/OSD/MGR, l’algorithme CRUSH, ce que sont les PG. Tu peux expliquer l’architecture sur un tableau blanc. Mais ton cluster a de mauvaises performances et tu ne sais pas si c’est le CPU, le réseau, les disques ou la configuration.
Symptôme typique : tu lis des articles sur le réglage de BlueStore, tu changes les paramètres au hasard, tu ne mesures pas l’avant et l’après. Les performances restent les mêmes (ou sont pires).
Année 1-2 : ” Je sais dépanner mais je n’ai pas de méthode “.
Tu as sauvé quelques clusters. Tu sais comment utiliser ceph health detail, interpréter les états de PG, récupérer un OSD en panne. Mais chaque problème est une nouvelle aventure de 4 heures d’essais.
Symptôme typique : tu peux régler les problèmes… éventuellement. Mais tu ne peux pas les prédire ou expliquer à ton patron combien de temps la solution prendra.
Année 2-3 : “J’ai de la méthode et je comprends les compromis”.
Tu diagnostiques systématiquement : collecter les symptômes, formuler des hypothèses, valider avec des outils spécifiques. Tu comprends les compromis : quand utiliser la réplication par rapport à l’erasure coding, comment dimensionner le matériel, quand NVMe est intéressant.
Symptôme typique : ta réponse aux problèmes est “laisse-moi vérifier X, Y et Z” avec un plan clair. Tu peux estimer des temps de récupération réalistes.
Année 3+ : une véritable expertise
Tu conçois des architectures à partir de zéro en tenant compte de la charge de travail, du budget et des accords de niveau de service. Tu fais de la reprise après sinistre sans manuel. Optimise BlueStore pour des charges spécifiques. Comprends suffisamment bien le code source pour déboguer les comportements rares.
Symptôme typique : d’autres administrateurs t’appellent quand un cluster est “impossible”. Il te faut 20 minutes pour identifier le problème qu’ils ont attaqué pendant 3 jours.
La bonne nouvelle : tu peux considérablement accélérer cette progression grâce à une formation structurée. Un bon cours de 3 jours peut condenser 6 mois d’essais et d’erreurs. Non pas parce qu’elle “enseigne plus vite”, mais parce qu’elle évite les impasses et les malentendus qui consomment des semaines.
Les malentendus typiques qui t’empêchent d’apprendre
Malentendu n° 1 : “Plus de matériel = plus de performances”.
J’ai vu des clusters avec 40 OSDs qui fonctionnaient moins bien que des clusters avec 12. Pourquoi ? Parce qu’ils l’ont fait :
- Réseau public et cluster sur la même interface (saturation garantie).
- Gouverneur de fréquence de l’unité centrale sur “powersave” (dégradation de 5x dans la réplication).
- Le nombre de PG est totalement déséquilibré entre les pools
- BlueStore : cache très bas pour les charges RGW
La réalité : les performances de Ceph dépendent du maillon le plus faible. Un goulot d’étranglement à un seul thread dans un MON peut faire tomber tout le cluster. Plus de matériel mal configuré ne fait que multiplier le chaos.
Malentendu n°2 : “Le codage par effacement permet toujours d’économiser de l’espace”.
Un jour, un élève a déclaré fièrement : “J’ai fait passer tout mon cluster à l’erasure coding 8+3 pour économiser de l’espace”. Nous lui avons demandé : “Quelle est ta charge de travail ?” – “RBD avec des snapshots fréquents”. Oups.
Le codage par effacement avec des charges de travail qui effectuent de petits écrasements (RBD, CephFS) est TERRIBLE pour les performances. Et les “économies” d’espace sont absorbées par les bandes partielles et la surcharge des métadonnées.
La réalité : EC est excellent pour les données froides du stockage d’objets (archives RGW). Il est nul pour les périphériques de bloc avec des IOPS élevés. Connaître la charge de travail avant de décider de l’architecture est fondamental.
Malentendu n° 3 : ” Si ceph health indique HEALTH_OK, tout va bien “.
Non. HEALTH_OK signifie que Ceph n’a pas détecté de problèmes connus de lui. Il ne détecte pas :
- Dégradation progressive du disque (avertissements SMART)
- Perte intermittente de paquets réseau
- Fuites de mémoire dans les démons
- Un nettoyage qui n’a pas été effectué depuis 2 semaines.
- Les PGs dont le placement n’est pas optimal causent des points chauds.
La réalité : tu as besoin d’un monitoring externe (Prometheus + Grafana minimum) et de revoir les métriques que Ceph n’expose pas sur ceph health. HEALTH_OK est nécessaire mais pas suffisant.
Malentendu n°4 : ” j’ai lu la doc officielle et ça suffit “.
La documentation officielle est un matériel de référence, pas un matériel d’enseignement. On part du principe que tu as déjà compris :
- Systèmes distribués (Paxos, quorum, consensus)
- Principes fondamentaux du stockage (IOPS vs débit, percentiles de latence)
- Réseau (MTU, trames jumbo, tuning TCP)
- Linux interne (cgroups, systemd, paramètres du noyau)
Si tu n’apportes pas cette base, le doc t’embrouillera plus qu’il ne t’aidera.
La réalité : Tu as besoin de ressources supplémentaires : des articles académiques sur les systèmes distribués, des blogs d’expériences réelles, des formations qui relient les points que la doc omet.
Les erreurs typiques (que nous commettons tous)
Les erreurs des débutants
Ne pas configurer le réseau du cluster : Le réseau public est saturé par la réplication interne. Les performances chutent. Solution : --cluster-network dès le premier jour.
Utiliser les valeurs par défaut pour le nombre de PG : Dans les versions antérieures au Pacifique, tu créais des pools avec 8 PG… pour un pool qui atteignait 50 To. Impossible de rééquilibrer par la suite. Solution : Autoscaler ou calculer dès le départ.
Ne pas comprendre la différence OSD up/down vs in/out : Tu sors un OSD pour maintenance avec ceph osd out et tu commences immédiatement un rééquilibrage massif qui dure 8 heures. Tu voulais
Erreurs intermédiaires
Codage par effacement surdimensionné : Configure 17+3 ECs dans une grappe de 25 nœuds. Un nœud tombe en panne et la grappe passe en mode lecture seule parce qu’il n’y a pas assez d’OSD sur lesquels écrire. Le compromis n’est pas compris.
Ignore le planificateur d’E/S : utilise le planificateur de délai avec NVMe (absurde). Ou aucun planificateur avec les disques durs (désastreux). Le bon planificateur compte pour 20 à 30 % de la performance.
Ne planifie pas la reprise après sinistre: “Nous avons une réplication 3x, nous sommes en sécurité”. Puis un rack entier tombe en panne et ils perdent le quorum des MON. Ils n’ont jamais pratiqué la récupération. Ils paniquent.
Les erreurs des experts (oui, nous en faisons aussi)
Over-tuning : modification simultanée de 15 paramètres de BlueStore “pour optimiser”. Quelque chose se casse. Lequel des 15 changements était-ce ? Personne ne le sait. Principe : changer UNE chose, mesurer, itérer.
S’appuyer trop sur de vieilles connaissances : appliquer les techniques de réglage de FileStore à BlueStore. Cela ne fonctionne pas parce que l’architecture interne est totalement différente. Le contexte historique est important.
Ne pas documenter les décisions architecturales : il y a 2 ans, tu as décidé d’utiliser EC 8+2 dans un certain bassin pour X raison. Personne ne l’a documenté. Maintenant, un nouvel administrateur veut “simplifier” la réplication. Un désastre que l’on peut éviter grâce à la documentation.
La voie la plus efficace pour apprendre Ceph
Phase 1 : Principes fondamentaux de l’architecture (40-60 heures)
Avant de toucher à une commande, comprends bien :
- Quel problème Ceph résout-il (par rapport à NAS, par rapport à SAN, par rapport au stockage en nuage) ?
- Architecture RADOS : comment fonctionnent MON, OSD, MGR
- Algorithme CRUSH : pourquoi existe-t-il, quel problème résout-il ?
- Groupes de placement : l’abstraction qui rend le système évolutif.
- Différence entre les pools, les PG, les objets et leur correspondance avec les OSD.
Comment l’étudier : pas avec des commandes, mais avec des diagrammes et des concepts. Un bon cours sur les fondamentaux est 100x plus efficace que les tutoriels “déployer en 10 minutes”.
Cours recommandé : administration Ceph
Niveau : fondamental
3 jours intensifs
Programme spécialement conçu pour construire une base solide à partir de zéro. Il ne suppose aucune connaissance préalable du stockage distribué.
Phase 2 : configuration avancée et dépannage (60-80 heures)
Avec des bases solides, tu peux maintenant aller plus loin :
- BlueStore : comment les données sont écrites en réalité
- Règles CRUSH personnalisées pour les topologies complexes
- Optimisation des performances : identifier les goulots d’étranglement
- RGW multi-sites pour la géo-réplication
- Mise en miroir du RBD pour la reprise après sinistre
- Dépannage systématique avec méthode
L’objectif : passer de ” je sais configurer ” à ” je comprends pourquoi je configure ainsi et quels sont les compromis que je fais “.
Cours recommandé : Ceph avancé
Niveau : avancé
3 jours intensifs
Pour les administrateurs qui ont déjà un cluster en fonctionnement mais qui veulent maîtriser des configurations complexes et se préparer à l’EX260.
Phase 3 : opérations productives critiques (80-100 heures)
Le saut final : de “je sais comment configurer et dépanner” à “je peux sauver des clusters en production à 3 heures du matin”.
- Dépannage judiciaire : diagnostiquer les pannes complexes à facteurs multiples.
- Récupération après sinistre REAL : récupération des métadonnées corrompues, des journaux perdus.
- Ingénierie des performances : optimisation du noyau et du matériel
- Architectures pour des charges spécifiques : AI/ML, streaming vidéo, conformité.
- Renforcement de la sécurité et conformité (GDPR, HIPAA)
- Passage à l’échelle des pétaoctets : les problèmes qui ne se posent qu’à grande échelle.
L’objectif : une véritable expertise vérifiable. Éliminer ce “respect” (cette peur) des scénarios critiques.
Cours recommandé : ingénierie de production Ceph
Niveau : expert
3 jours intensifs
Le seul cours sur le marché axé à 100 % sur les opérations de production critiques. Pas de simulations – de vrais problèmes.
Pratique continue : l’ingrédient non négociable
Voici la vérité qui dérange : tu peux suivre les 3 cours et n’avoir aucune expertise si tu ne pratiques pas. Les connaissances théoriques sont oubliées si tu ne les appliques pas.
Recommandation de SIXE après chaque cours :
- Mets en place une grappe d’entraînement (il peut s’agir de VM locales ou d’un nuage bon marché).
- Casse intentionnellement les choses: tue les OSD, remplit les disques, sature le réseau.
- Pratique la récupération sans manuel: peux-tu récupérer sans Google ?
- Mesure tout: repères avant/après chaque changement
- Documente ton apprentissage: blog, notes, etc.
Conseil de pro : les meilleurs administrateurs Ceph que je connaisse gardent en permanence un “cluster de laboratoire” où ils testent des choses folles. Certains ont même des scripts qui injectent des bogues aléatoires pour s’entraîner au dépannage. Cela peut sembler extrême, mais ça marche.
Conclusion : la route est longue mais peut être accélérée.
Si tu es arrivé jusqu’ici, tu es déjà dans le top 10 % des administrateurs Ceph par pure intention d’apprendre correctement. La plupart abandonnent lorsqu’ils se rendent compte de la complexité réelle.
Les vérités inconfortables que tu dois accepter :
- La maîtrise de Ceph nécessite 2 à 3 ans d’expérience pratique continue. Il n’y a pas de raccourcis magiques.
- Tu vas faire des erreurs. Beaucoup d’entre elles. Certaines dans la production. Cela fait partie du processus.
- Les connaissances se déprécient rapidement. Ce que tu apprends aujourd’hui sera partiellement obsolète dans 18 mois.
- La documentation officielle ne sera jamais adaptée aux tutoriels. Tu as besoin de ressources complémentaires.
Mais il y a aussi de bonnes nouvelles :
- La demande d’experts Ceph dépasse massivement l’offre. C’est le bon moment pour se spécialiser.
- Tu peux accélérer la courbe d’apprentissage de 6 à 12 mois avec une formation structurée qui évite les impasses.
- Une fois que tu as “cliqué” sur l’architecture fondamentale, le reste se construit logiquement sur cette base.
- La communauté est généralement ouverte à l’aide. Tu n’es pas seul(e).
Notre dernier conseil après plus de 10 ans avec Ceph : commence par des principes fondamentaux solides, entraîne-toi constamment et n’aie pas peur de casser des choses dans des environnements de test. Les meilleurs administrateurs que je connaisse sont ceux qui ont cassé le plus de clusters (en laboratoire) et qui ont méticuleusement documenté chaque récupération.
Et si tu veux accélérer considérablement ta courbe d’apprentissage, envisage une formation structurée qui condense des années d’expérience pratique en semaines intensives. Non pas parce que c’est plus facile, mais parce que cela t’épargne les 6 mois que nous perdons tous à nous attaquer à des problèmes que quelqu’un d’autre a déjà résolus.
Par où commencer aujourd’hui ?
- Si tu es totalement débutant : cours d’administration Ceph.
- Si tu gères déjà un cluster : cours Ceph avancé
- Si tu as plus de 2 ans et que tu veux une vraie expertise : ingénierie de production Ceph.
Ou alors, il suffit de mettre en place un cluster de 3 VM, de casser des choses et d’apprendre à dépanner. Le chemin est le tien, mais il ne doit pas être solitaire.


