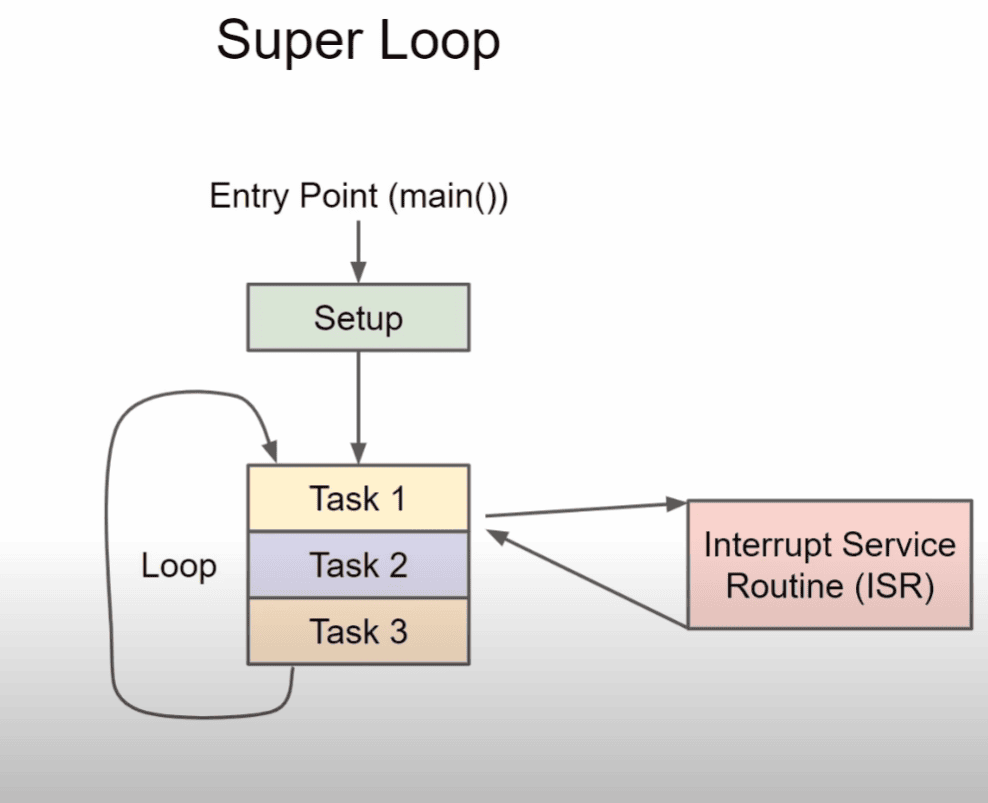
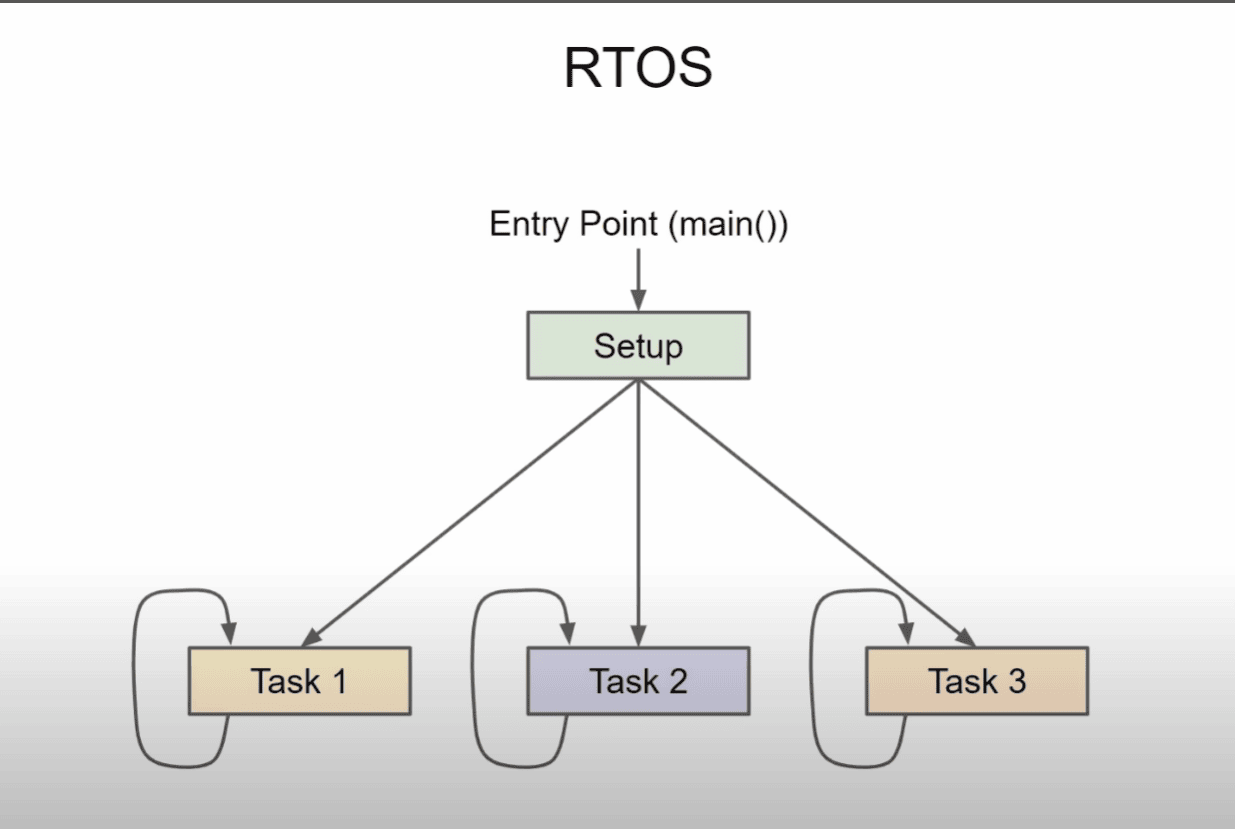
Pourquoi est-il crucial d’effectuer un healtcheck d’AIX ?
Sais-tu que de nombreux systèmes AIX fonctionnent bien jusqu’à ce qu’ils cessent soudainement de fonctionner ??
Ce qui est amusant, c’est que les problèmes donnent presque toujours un avertissement, mais… les écoutes-tu ? ? Si tu veux découvrir comment un simple bilan de santé peut t’aider à détecter ces avertissements précoces et à prévenir les défaillances critiques avant que ton AIX n'”implose”, lis la suite.?
La health- quoi ?
Un healthcheck est un examen rapide et préliminaire de l’état d’un système. Son principal objectif est de donner un aperçu des performances, de la stabilité et de la sécurité du système afin d’identifier les domaines qui nécessitent une attention immédiate. Contrairement à un audit complet, qui est beaucoup plus détaillé et approfondi, le healthcheck est une étape initiale qui permet de déterminer “l’état de santé” du système de manière agile et efficace. Et en plus… Chez SIXE, nous réalisons des bilans de santé. Demande-le ici
Quel est l’objectif d’un healthcheck d’AIX ?
Le bilan de santé AIX est une évaluation technique axée sur l’examen des aspects clés du système, tels que l’utilisation des ressources, la santé du matériel, les journaux d’erreurs et la sécurité de base. Ce processus permet d’identifier les problèmes potentiels et les priorités d’intervention sans entrer dans le niveau de détail d’un audit complet. Voici quelques points clés couverts par un bilan de santé AIX:
- Performance globale : Évaluation de l’utilisation de l’unité centrale, de la mémoire et du stockage pour identifier les goulets d’étranglement et les domaines à améliorer.
- État du matériel : détection des défauts ou des composants dégradés qui peuvent affecter la stabilité du système.
- Erreurs récurrentes : Examen des journaux du système (errpt, syslog) pour identifier les modèles d’erreurs et d’anomalies qui peuvent indiquer des problèmes sous-jacents.
- Conformité à la sécurité de base : vérification des paramètres clés tels que l’accès, les permissions des utilisateurs et les politiques de mot de passe, pour s’assurer que le système est protégé contre les accès non autorisés.
Cette analyse préliminaire est particulièrement utile pour les entreprises qui ont besoin d’un diagnostic initial pour déterminer les aspects à aborder ultérieurement, soit par une optimisation spécifique, soit par un audit complet.
Pourquoi effectuer un healthcheck d’AIX ?
1. identifier rapidement les problèmes critiques
Le healthcheck sert d’alerte précoce pour détecter les défauts ou les faiblesses qui pourraient entraîner des perturbations majeures. Par exemple :
- Les processus qui consomment trop de ressources.
- Les configurations dangereuses ou inappropriées.
- État des disques durs, de la mémoire et des autres composants critiques du système.
2. Optimiser les ressources
Il te permet de trouver les configurations qui limitent les performances du système, comme une utilisation excessive de l’unité centrale ou un stockage mal réparti. Cela aide à faire des ajustements rapides qui améliorent l’opérabilité sans avoir recours à des mesures plus complexes.
3. Fixer les priorités
Le résultat du healthcheck fournit un point de départ clair pour planifier les actions futures : de la mise en place de correctifs à un audit plus détaillé.
Outils utiles pour un healthcheck d’AIX
Voici quelques outils et commandes qui peuvent simplifier le processus :
- nmon: pour une analyse détaillée des performances.
- errpt: pour identifier les erreurs matérielles et logicielles.
- topas: pour surveiller les ressources en temps réel.
- PowerSC: Pour revoir les paramètres de sécurité.

À quoi s’attendre en tant que client du healthcheck d’AIX ?
Comment fonctionne un healthcheck AIX, que dois-je demander, en quoi cela va-t-il m’aider ? En tant que client, tu recevras un rapport détaillé sur l’état de ton environnement en termes de sécurité, de performance, de disponibilité et de suggestions d’amélioration. Le processus comprend des recommandations claires et pratiques pour optimiser ton système, améliorer la sécurité et garantir que ton AIX fonctionne efficacement. Ce rapport t’aidera non seulement à prévenir les problèmes futurs, mais il te fournira également un plan d’action concret pour améliorer les performances et maintenir ton infrastructure protégée et opérationnelle.
Conclusion
Un healtcheck est la première étape pour s’assurer qu’un système fonctionne correctement et efficacement. Il agit comme un “healthcheck” qui identifie les problèmes et les priorités, fournissant ainsi une base solide pour des décisions plus complexes, telles qu’un audit complet ou l’optimisation des ressources. En bref, effectuer cet examen simple et rapide permet de gagner du temps, d’éviter des problèmes majeurs et de s’assurer que le système est dans un état optimal pour répondre aux besoins opérationnels de l’organisation. Si tu veux que nous effectuions un healtcheck de ton système AIX , tu peux en faire la demande ici https://sixe.es/sistemas/consultoria/healthcheck-de-sistemas-aix